Easy high performance tables with reflection data binding
July 20, 2011
java swing jtable tablesCode can be found on Github - https://github.com/ivanporty/swingtools.
Swing’s JTable is an extremely powerful component. It allows you do to almost everything with it, include any other components, draw and edit in each cell differently etc. Its model, TableModel, is not complex, but it requires certain amount of very boring and boilerplate code to implement a table for many situations. Most of the time, you have a list of objects where a single object presents one row in a table, and columns values are mapped to properties of that object. And for every new object type and new table, you have to write your TableModel yourself, repeating these lines of code again and again:
public class SimpleTableModel extends AbstractTableModel {
private List data = new ArrayList();
@Override
public int getRowCount() {
return data.size();
}
@Override
public int getColumnCount() {
return 10;
}
@Override
public Object getValueAt(int rowIndex, int columnIndex) {
switch (columnIndex) {
case 0:
// either toString() or a slightly different data processing
return data.get(rowIndex).toString();
// many more case,case,case for each column...
default:
return "";
}
}
}
In general case, you only need those three methods to have a working table, if you’re satisfied with Excel-like column titles ‘A’, ‘B’,…,’AB’ etc. Most of the time titles are needed to be implemented as well, so this means another annoying ‘switch/case’ or preparing a list of column names so that they could be obtained by the index. There are no helper methods to obtain them directly from resources and that means you need to maintain table column names both in the code and in the resource bundle.
For smaller tables it seems OK to use the technique above, but if you have quite a few of them, writing the same code again and again become boring and that’s a good ground for starting to use notorious ‘copy-paste’ which means a lot of subtle bugs later. For large tables the code is monotonous set of large ‘switch/case’s, ‘if’s etc., which again is extremely low-level work and a fertile soil for a lot of bugs and mistypes. The worse thing is changing such models later, when you have different column order, names, or underlying data object has been re-factored and its properties are changed. It’s quite easy to introduce bugs and forget about many small things.
The obvious solution would be assigning columns directly to properties of an underlying data bean. The properties themselves have type which could become a type of a column – and that means automatic selection of an appropriate renderer and editor. It’s not hard at all to build such a table model and use it later for most of your table implementations.
public class BeanPropertyTableModel<T> extends AbstractTableModel {
// class of the data in rows
private final Class beanClass;
// collection of table rows
private List<T> data = new ArrayList<T>();
// collection of column property descriptors
private List<PropertyDescriptor> columns = new ArrayList<PropertyDescriptor>();
public BeanPropertyTableModel(Class beanClass) {
if (beanClass == null) {
throw new IllegalArgumentException("Bean class required, cannot be null");
}
this.beanClass = beanClass;
populateColumns();
}
public List<T> getData() {
return data;
}
public void setData(List<T> data) {
this.data = data;
fireTableDataChanged();
}
@Override
public int getRowCount() {
return data.size();
}
@Override
public Class<?> getColumnClass(int columnIndex) {
return columns.get(columnIndex).getPropertyType();
}
@Override
public String getColumnName(int column) {
return columns.get(column).getDisplayName();
}
@Override
public int getColumnCount() {
return columns.size();
}
@Override
public Object getValueAt(int rowIndex, int columnIndex) {
PropertyDescriptor descriptor = columns.get(columnIndex);
T bean = data.get(rowIndex);
return DynamicBeanUtils.getPropertyValue(
bean, descriptor);
}
private void populateColumns() {
BeanInfo info = null;
try {
info = Introspector.getBeanInfo(beanClass);
} catch (IntrospectionException ex) {
throw new RuntimeException(
"Unable to introspect bean class", ex);
}
PropertyDescriptor[] pds = info.getPropertyDescriptors();
columns.addAll(Arrays.asList(pds));
}
}
This is again a simple table model derived from AbstractTableModel class which does some event support and stub methods for us. We have to pass a class of the bean we’re going to show in the table into the constructor as generics type erasure won’t let us know the type of T. Upon creating a model we get all properties available in the bean with the help of core JDK BeanInfo class. Every property is described by a PropertyDescriptor. Numbers of properties in the bean becomes number of columns. When passed a new list of beans into setData(), the model notifies listeners that its data has been changed.
The only interesting thing is how to get a property value. This is pretty easy and separated to be in own utility class as we may need it later:
public class DynamicBeanUtils {
public static <T> T getPropertyValue(Object instance, PropertyDescriptor descriptor) {
try {
Method m = descriptor.getReadMethod();
Object result = m.invoke(instance);
return (T) result;
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
}
There are no reasons to catch any exceptions here and they shouldn’t be thrown as bean properties are supposed to be accessible and public, so we’re converting them into unchecked ones.
This very initial and simple implementation is already able to show list of arbitrary beans with all of their properties as columns in the table. For example, if we take the following test Java bean class:
public class TableBean {
private String name, surname;
private Date date;
...
getters/setters
}
And create a large list of its instances with randomly generated strings and data, we’ll see the following:
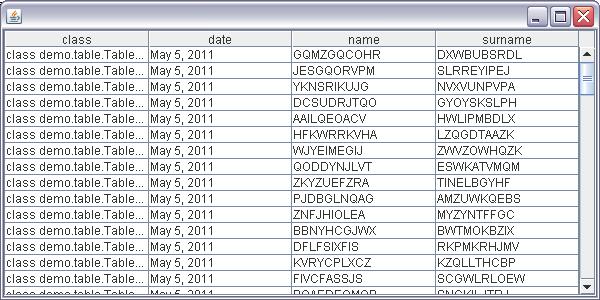
The only code to create this table is:
JTable table = new JTable();
add(new JScrollPane(table));
BeanPropertyTableModel<TableBean> model = new BeanPropertyTableModel<TableBean>(TableBean.class);
model.setOrderedProperties(Arrays.asList(“name”,”surname”,”date”));
model.setData(TableBean.generateList(100));
table.setModel(model);
We see that date property is recognized and properly rendered thanks to its column class, and property names are used as column names. The bad thing is BeanInfo class returns property descriptor for ‘class’ property which of course exists in any Java object (there’s getClass() method) but doesn’t belong to actual properties of an object. It makes sense to add a concept of excluded properties which would allow us to exclude certain properties from showing as columns. ‘class’ property will always be excluded.
The other thing is the order of columns on the screen. It’s not strictly specified by the language or compiler or virtual machine, but since the very early days of Java beans and reflection it’s always been alphabetic order of their names. Order of properties in the source file is discarded when compiler does its work. Most of the time users want to see certain order of columns on screen, so another feature of bean property model should be an ability to specify order of its properties. This is just a simple list of names and it makes sense to load it from application resource file. Also, in order to specify custom rendering for certain columns and manipulate them in other way we need to know which index has the column mapped to specific property.
And the last important thing would be reading column names from resource bundle using some prefix and property name. Most of the time you’ll have to do that as property names rarely work well as screen names even if you split them by words using appropriate cases.
Having added all of that quite primitive but useful functionality into our new BeanPropertyTableModel, we end up with the following laconic API to build flexible and powerful tables with any data in a matter of seconds:
setResourceBundle(ResourceBundle)
setResourcePrefix(String)
addExcludedProperty(String)
setOrderedProperties(List<String>)
Having all the API in place and adding just one new line model.setOrderedProperties(Arrays.asList(“name”,”surname”,”date”)); we can enjoy grown up table which behaves exactly just like we’d described it s model completely from scratch for a particular Java bean.
Tables often become victim of poor performance, especially for large number of columns and complex data types. What about our new property table model? Some may remember the rumors on Java reflection poor performance, and for the large, many columns and rows table we definitely will use a lot of reflection calls to access the properties. But, in recent versions of JDK reflection performs really well and won’t be an issue comparing to usual graphics/painting overhead, more than that, JDK will replace reflection calls with bytecode pretty quickly as it discovers we’re using a lot of calls to the same methods to get the properties values.
Are there any similar alternatives? One of the common solutions to quickly build tables and bind them to properties is Beans Binding library, which does not allow you to quickly show all of the bean properties as our model does, but you can add column using EL language syntax and even access inner properties inside of properties.
However, some of my experiments clearly showed insufficient performances of Beans Binding for large tables, especially if tables are read only and the bean itself does not notify listeners on changes on every single property which is supposed to be extremely fast. Simple and small table model from this article perform much faster and you can visibly see the difference, especially in scrolling. The most painful part with Beans Binding is reloading the whole data list – it takes time on event dispatch thread to re-build listeners and visibly slows down your application whenever large list of rows for a table arrives. There is no way you can make your table as fast as manually created table which gets its data from directly calling methods of objects known at compile time when you use Beans Binding, but the simple reflection model used in this article comes very close and saves tons of time especially when it comes to prototyping or hundreds of tables in the application. Use this model for the tables of any size and any frequency of updates and still have power of binding and dynamic at hand.